Bug #9270
closed'Unique IDs' are not unique
100%
Description
While tracking an issue in my project I stumbled over the WObject ID creation, which is done by incrementing a static counter (an unsigned value) every time a WObject is created. Incrementing an unsigned value is not atomic and thus the counter is not thread safe. Concurrently creating multiple WObject's at the same time can (and will) mess up the counter, resulting in duplicated and thus no longer unique IDs.
I decided to write a small test program to verify the issue; the associated files are attached to this ticket. I simply launched several threads that create tens of thousands of WContainerWidget instances. After the creation is finished, I simply check the (string) IDs of the created objects for uniqueness - firstly for objects created subsequently by the same thread, as it would occur within a WApplication instance if WApplication::UpdateLock is used properly; secondly for all objects created by any thread. The test was performed on an AMD Ryzen 9 3950X 16 core / 32 thread processor. I expected some rare duplicated IDs. My first test was done with Visual Studio 2022 on Windows 11 and I was extremely surprised by the result. I attached a file containing the complete output. Here is just a small excerpt:
task #0: 99364 of 100000 ids are unique
task #1: 99379 of 100000 ids are unique
task #2: 99404 of 100000 ids are unique
...
task #98: 99180 of 100000 ids are unique
task #99: 99213 of 100000 ids are unique
overall: 9138068 of 10000000 ids are unique
As you can see, about 0.5-1% of all objects created within the same thread had duplicated IDs (for every single thread) and about 10% of all objects created had non-unique IDs. I reran the test multiple times and while the exact numbers varied, the overall picture remained the same. I also reran the test on WSL2 Ubuntu. The percentages were significantly lower (probably due to different thread scheduling and/or different optimization levels), but the issue was still existent:
task #0: 99895 of 100000 ids are unique
task #1: 99954 of 100000 ids are unique
task #2: 99881 of 100000 ids are unique
...
task #98: 99949 of 100000 ids are unique
task #99: 99924 of 100000 ids are unique
overall: 9909523 of 10000000 ids are unique
Some more digging revealed that EventSignalBase, JSlot and DomElement use the same flawed ID functionality. This is pretty bad, since Wt relies on the uniqueness. While there are certainly several more potential issues, some problems that come to mind are:
WApplication::encodeObjectuses the ID as map key, which needs to be unique; otherwise mapped objects may just be overwritten.- Exposed signals rely on unique IDs.
WObjectIDs are used for HTMLidattributes. Using the same ID multiple times, while tolerated by most browsers, is not valid HTML5 and can mess up javascript/CSS functionality that selects elements by ID.
I already implemented fixes for these issues, by replacing the IDs with std::atomic<> values. Rerunning the tests with applied fixes delivered the desired results:
task #0: 100000 of 100000 ids are unique
task #1: 100000 of 100000 ids are unique
task #2: 100000 of 100000 ids are unique
...
task #98: 100000 of 100000 ids are unique
task #99: 100000 of 100000 ids are unique
overall: 10000000 of 10000000 ids are unique
Since atomic values need locking and thus are more expensive than the previous version, I implemented a quick test that measures the time needed to create 5 million WContainerWidget instances on a single thread, automatically repeated it 10 times and compared the mean duration. I performed several test runs and there was hardly any noticeable difference. Both versions usually lie within 1-2% of each other. Considering that the fixed version actually guarantees uniqueness, while the original version does not, this is more than acceptable in my opinion. The exact measurements are contained in the attached logs.
I also made the ID counters unsigned, since possible overflows due to increasing the counters over and over again are undefined behavior for signed integers, and I applied some updates to ID to string conversion, since the original version converts an unsigned ID to a signed value while building the string, which produces invalid string representations.
Sorry for the wall of text, but I thought that issue was important/serious and needed some proper demonstration. I will create a pull request containing the fixes shortly and would be happy if you could merge it in the repository, after you evaluated it. Please don't hesitate to ask if you need further information or if you have any further questions.
Best regards from Hamburg
Steven
Files
{kind=link}
Updated by Steven Köhler over 2 years ago
Created the pull request for this issue: https://github.com/emweb/wt/pull/183
Updated by Steven Köhler over 2 years ago
This issue is related to an issue Roel created about a year ago: https://redmine.webtoolkit.eu/issues/7898. Unfortunately the previous assessment, that only IDs within different application objects are affected, seems to be incorrect - as shown above.
Updated by Roel Standaert over 2 years ago
- Target version set to future
Hm, so my (and probably Koen's) assertion that this would not occur within a WApplication was wrong?
I don't immediately see the first test you mention in your main.cpp? The one you refer to here:
firstly for objects created subsequently by the same thread
Updated by Steven Köhler over 2 years ago
I added some comments and the time measurement to main.cpp. The timer should work with Visual Studio and GCC.
I don't immediately see the first test you mention in your main.cpp?
I basically spawn 100 threads that each create and return a std::vector containing 100k WContainerWidget instances. After all threads are finished, I spawn another 100 threads that each build and return a ´std::vector´ containing the string IDs for one of the WContainerWidget vectors. Each of these vectors thus contains only the IDs of the widgets that were created by the same thread (aka widgets created inside one instance of WApplication with proper UpdateLock), different vectors always contain the widgets IDs from different threads. Additionally to creating the string IDs each of these threads also removes duplicates. If no duplicated IDs existed, each of these string vectors would contain 100k IDs. After all threads are finished, I print the number of unique IDs for each of the string vectors (I could do that inside the the threads as well, but it messes up the output without proper synchronisation). Finally, I merge all string IDs into one vector, remove duplicates again (duplicates from different threads) and print the number of unique IDs, which should be 100*100k if no duplicates existed at all.
Hm, so my (and probably Koen's) assertion that this would not occur within a WApplication was wrong?
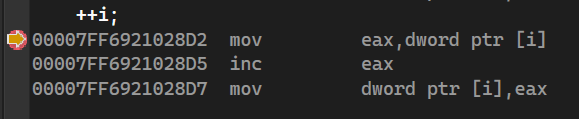
I think so, yes. Incrementing is basically done in 3 steps: load, inc, store (see inc.png). Consider there are two threads A and B. cnt is the static counter, cntA and cntB the current value inside threads A and B. The operations could be intermixed like this:
1: thread A: load // cnt=42, cntA=42
2: thread B: load // cnt=42, cntB=42
3: thread B: inc // cnt=42, cntB=43
4: thread B: store // cnt=43
5: thread B: create object with ID 42
6: thread B: load // cnt=43, cntB=43
7: thread B: inc // cnt=43, cntB=44
8: thread B: store // cnt=44
9: thread B: create object with ID 43
10: thread A: inc // cnt=44, cntA=43
11: thread A: store // cnt=43
12: thread A: create object with ID 42 (duplicated ID 42 in threads A and B)
13: thread B: load // cnt=43, cntB=43
14: thread B: inc // cntB=44
15: thread B: store // cnt=44
16: thread B: create object with ID 43 (duplicated ID 43 in thread B)
Threads A and B could both load the static value before it is modified by one thread (1,2). Thread A goes to sleep for a moment, thread B continues to increment the counter, store the new value and create the widget with ID 42 (3-5) - assuming the not-incremented cnt value is used as ID. Static counter would be 43 by now. Then thread B does this again, static counter is incremented to 44 and widget with ID 43 is created (6-9). Now thread A with already loaded ID 42 increments its (outdated) counter value to 43, stores it (11) and creates a widget with ID 42 (12). This results in two widgets with duplicated IDs in different threads. The real problem is (11), where the static counter, that was already incremented to 44 by B, is now overwritten with the lower value 43 by A. In (13-16) thread B now loads the old (and previously used) value 43, increments it and creates a widget with ID 43, which is now a duplicated ID created inside the same thread B - the case you assumed would not happen. There are also possibilities for this to happen if more than 2 threads are involved, but the above example should suffice. The more threads are involved, the higher the chances, that this happens. While this is just a theoretical consideration, the test program shows that this actually happens.
Updated by Roel Standaert over 2 years ago
- Target version changed from future to 4.7.0
Aha, I see how that scenario may lead to (rare) conflicts indeed. I put it on the roadmap. The straightforward answer would indeed be to use an atomic counter, and I imagine the overhead will be negligible. One alternative would be to have completely random ids, which, if they are large enough, are extremely unlikely to ever have a conflict, but that may not actually end up being more efficient than an atomic counter.
Updated by Steven Köhler over 2 years ago
I'd like to add some thoughts regarding the random IDs:
- An atomic counter is guaranteed to deliver unique IDs, whereas random IDs are only most likely unique.
- Random number generation is not free either.
- Thread safe random number generation adds way more complexity than atomic counters.
- C++ (default) random engines from
<random>header (usually a mersenne twister) are not thread safe, so there would be a need for additional synchronization to prevent duplicated IDs in different threads, which alone probably costs more than the atomic counter. Even if duplicated IDs were acceptable, the mersenne twister needs to recalculate blocks of random numbers regularly, which will get messed up if triggered from different threads without synchronization. - By my understanding you currently store the (never changing) ID as integer and build the string representation each time the
WObject::id()function is called. Using a 'large enough' random ID, especially if bigger than the 32 bits, will increase the costs of each of these invocations too, which has to be considered for overall performance. (Is there a reason why you create the string ID on each invocation instead of just storing it?)
I did a quick performance test for atomic counters by just incrementing a counter in a loop. On my system, the loop for (size_t k=0; k < 1'000'000'000; ++k) { ++counter; } with an atomic counter took around 20 times longer than a non-atomic counter, which is not horribly much considering how cheap incrementing an integer is and how much more work (including really expensive memory allocations) is done when creating a widget. As mentioned in my initial report, my tests showed basically no performance difference between the atomic and non-atomic versions. Sometimes the atomic version ran a few ms faster, sometimes the non-atomic one.
So, if I get a say in it, I'd vote for the atomic vesion.
Updated by Roel Standaert over 2 years ago
- Status changed from New to Resolved
- Target version changed from 4.7.0 to 4.6.0
- % Done changed from 0 to 100
Updated by Roel Standaert over 2 years ago
- Target version changed from 4.6.0 to 4.5.2
Updated by Roel Standaert over 2 years ago
- Status changed from Resolved to Closed